给 Claude Code 写一个实时多行状态栏(Python statusLine)
这是什么
Claude Code 终端底部有一行 status line,默认信息比较少。它支持自定义:你给它一个命令,Claude Code 每次刷新时把一段 JSON 从 stdin 喂给这个命令,命令打印什么,状态栏就显示什么。
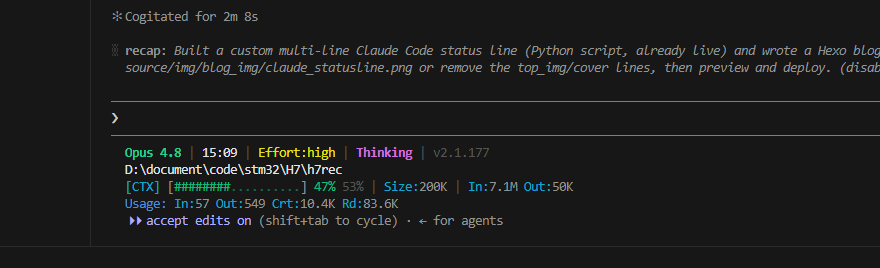
我把它做成了下面这样的四行状态栏(实时刷新):
claudecodeStatusline
1 | GLM-5.1 | 15:04 | Effort:high | Thinking | v2.1.126 |
逐行说明:
- 模型名 · 时间 · Effort 等级 · Thinking 开关 · 版本号
- 当前工作目录(完整路径)
- 上下文进度条:已用百分比 / 剩余百分比 | 上下文窗口大小 | 整个会话累计的输入/输出 token
- Usage:最近一次回复的 token 明细(输入 / 输出 / 缓存写入 / 缓存读取)
进度条颜色随使用率变化:绿(<50%)→ 黄(50–79%)→ 红(≥80%)。
数据从哪来
这是整件事最关键的部分,因为不同字段来源不一样。
1. stdin 的 JSON(Claude Code 每次刷新都给)
状态栏脚本启动时,Claude Code 会从标准输入塞一段 JSON 进来,常用字段:
| 字段 | 含义 |
|---|---|
.model.display_name |
模型显示名 |
.version |
Claude Code 版本号 |
.workspace.current_dir |
当前目录 |
.cwd |
当前目录(备用) |
.transcript_path |
当前会话的对话记录文件路径(JSONL) |
模型名、版本、目录直接从这里取就行。
2. transcript JSONL(token 数据的真正来源)
token 用量不在 stdin 的 JSON 里。但 .transcript_path 指向的那个 .jsonl 文件,每一行是一条消息,助手消息里带一个 usage 块:
1 | { |
于是脚本逐行读这个文件:
- 上下文已用 = 最后一条消息的
input_tokens + cache_creation + cache_read,再除以上下文窗口得到百分比; - 累计 In/Out = 把每条消息的 usage 全部累加。
3. Effort 等级(实时读 settings.json)
这是个坑。/effort 命令切换的等级,Claude Code 并没有通过 stdin 传给状态栏。一开始我用一个静态文件存它,结果发现切换 effort 后状态栏不跟着变。
后来定位到:/effort 实际把等级写进了 ~/.claude/settings.json 的 effortLevel 字段。所以脚本每次刷新直接读这个文件,就能做到真·实时——/effort 一切换,状态栏立刻更新。
4. Thinking 开关
这个 Claude Code 没有持久化到任何可读的地方,所以脚本用一个可选文件 ~/.claude/statusline-thinking 来控制显示(内容写 off 就隐藏),默认显示。
为什么用 Python 而不是 bash
状态栏的常规做法是 bash + jq 解析 JSON。但我这台机器没装 jq,而要解析 transcript 的嵌套 JSON、逐行累加 token,纯 sed/grep 很容易出错(我第一版就踩了,两个进度条会取到同一个值)。系统里有 Python 3.12,直接用 Python 解析 JSON 又稳又好维护,所以换成了 Python。
完整脚本
保存为 ~/.claude/statusline-command.py:
1 | #!/usr/bin/env python3 |
怎么设置
第一步:放脚本
把上面的脚本保存为:
1 | ~/.claude/statusline-command.py |
Windows 上
~就是C:\Users\你的用户名,所以完整路径是C:\Users\你的用户名\.claude\statusline-command.py。
第二步:在 settings.json 里启用
编辑 ~/.claude/settings.json,加上 statusLine 字段:
1 | { |
如果 python 命令不在 PATH 里,就换成 Python 的完整路径,比如"command": "C:/Users/你的用户名/AppData/Local/Programs/Python/Python312/python.exe ~/.claude/statusline-command.py"。
保存后状态栏会在下一次交互时自动变成新样式,无需重启。
第三步(可选):调整
- 上下文窗口大小:默认按 200K 算。如果你的模型窗口不是 200K,设个环境变量
CC_CTX_WINDOW,比如CC_CTX_WINDOW=1000000。 - 隐藏 Thinking:新建文件
~/.claude/statusline-thinking,内容写off。 - 进度条样式:改
bar()函数里的'#'和'.',或者slots(格子数)。
自己测试一下
写完脚本想确认它能跑,不用真的进 Claude Code,直接喂一段 JSON 给它(注意要带上真实的 transcript 路径才会有 token 数据):
1 | echo '{"model":{"display_name":"GLM-5.1"},"version":"2.1.126","workspace":{"current_dir":"C:/Users/Alan"},"transcript_path":"你的某个会话.jsonl的路径"}' | python ~/.claude/statusline-command.py |
能打印出四行带颜色的文字就说明成功了。
踩过的坑
- 没有 jq 不要硬上 sed。纯文本解析嵌套 JSON 很脆,两个进度条取到同一个值是我第一版的真实 bug。有 Python 就用 Python。
- effort 不在 stdin 里。别从 stdin 找它,去读
settings.json的effortLevel,这样才实时。 - Windows 路径转义。脚本里读文件用
os.path.expanduser("~/..."),跨平台都能用;测试时拼 JSON 字符串注意反斜杠转义。 - 状态栏脚本要快、要静默。它会被频繁调用,任何异常都要吞掉(脚本里全程
try/except兜底),否则状态栏会闪报错。
小结
Claude Code 的 statusLine 本质就是「给它一个命令,它喂 JSON,你打印字符串」。把 stdin JSON、transcript JSONL、settings.json 三个数据源拼起来,就能做出一个信息密度高、还实时刷新的状态栏。核心就一个脚本 + settings.json 里三行配置。